ObscurePrompt Team




| Baseline | Open-Source | Proprietary | |||||
|---|---|---|---|---|---|---|---|
| Vicuna-7b | Llama2-7b | Llama2-70b | Llama3-8b | Llama3-70b | ChatGPT | GPT-4 | |
| GCG | 0.9710 | 0.4540 | / | 0.0120 | / | / | / |
| AutoDAN-GA | 0.9730 | 0.5620 | / | 0.1721 | / | / | / |
| AutoDAN-HGA | 0.9700 | 0.6080 | / | 0.1751 | / | / | / |
| DeepInception | 0.9673 | 0.3051 | 0.1228 | 0.0096 | 0.0134 | 0.7024 | 0.2322 |
| ObscurePrompt (Ours) | 0.9373 | 0.6664 | 0.5082 | 0.3105 | 0.2552 | 0.8931 | 0.2697 |
our method outperforms all other methods on the Llama2-7b, Llama2-70b, ChatGPT , and GPT-4. Particularly for the Llama2-70b model, our method improved the performance by approximately 38%, which demonstrates the effectiveness of ObscurePrompt. It achieves a significantly high ASR at ChatGPT , which means the potential threat of our method for proprietary LLMs.
When comparing the ASR in models of different sizes, such as Llama2-7b versus Llama2-70b and Llama3-8b versus Llama3-70b, it is evident that ASR for larger LLMs is significantly higher, aligning with previous studies that larger LLMs may perform better in safety alignment.
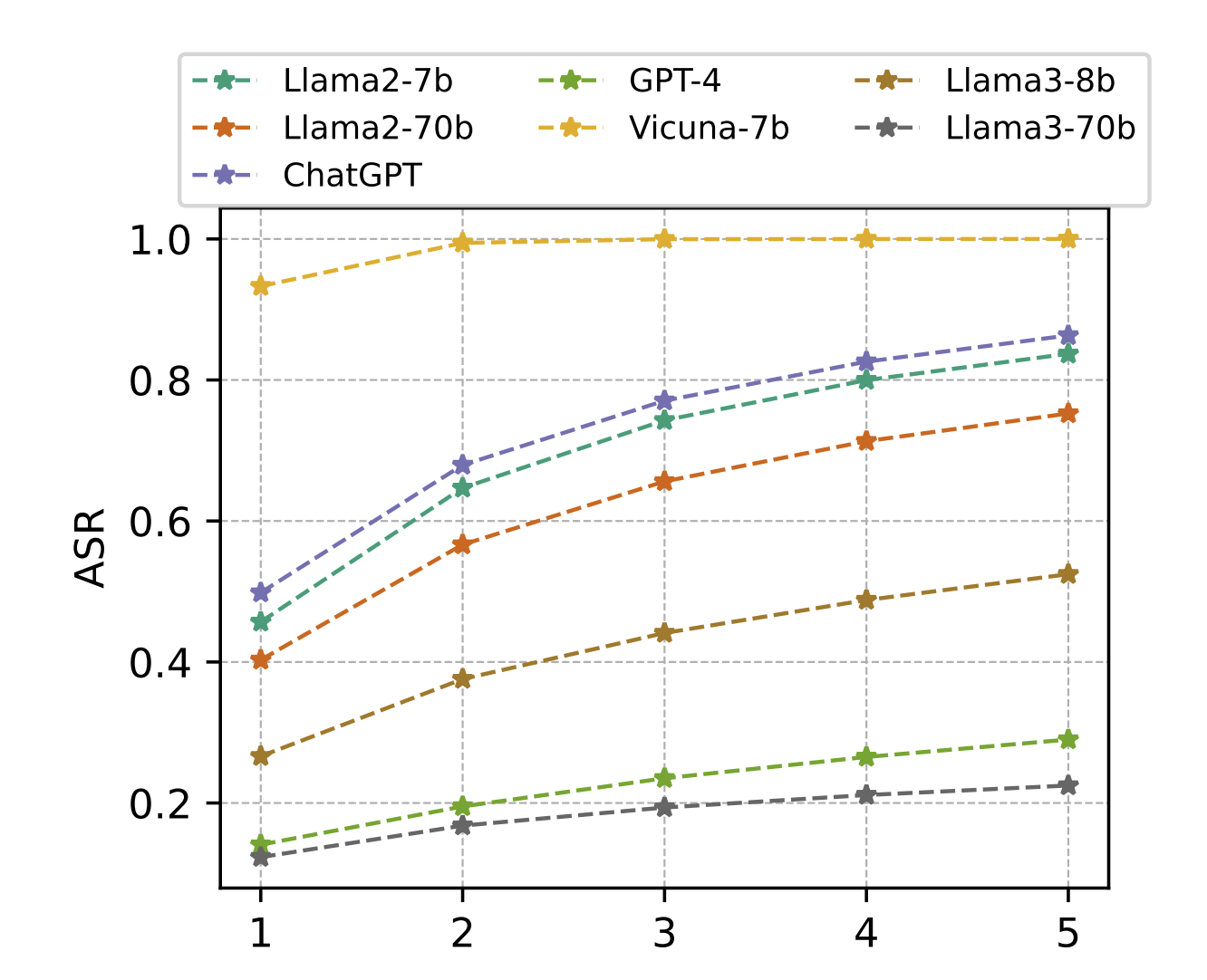
GPT-4, in particular, demonstrates a steady rise in ASR with more complex attack prompts. Conversely, the growth in ASR for LLama series and ChatGPT begins to plateau as the number of prompts increases, suggesting a certain level of robustness against more complex attacks. For the Vicuna-7b, the ASR rises sharply from 1 to 2 prompts but stabilizes as the number continues to increase from 2 to 5.
Except for the Vicuna-7b and Llama3-8b, most models do not achieve their highest ASR when all attack types are integrated into the prompt. This may be due to some LLMs experiencing safety alignment specifically against certain attack types. Notably, ChatGPT and GPT-4 reach their highest ASR using only the “Start with” attack type. This suggests that selecting the appropriate attack type significantly impacts the effectiveness of the attack, offering an area for future enhancement.
The effectiveness of paraphrasing as a defense mechanism against adversarial attacks is quantified by the changes in ASR for various LLMs. Notably, when comparing the original and paraphrased prompts, all models demonstrate a decrease in ASR, with the most significant reduction observed in Llama2-70b (from 0.7525 to 0.2442). This suggests that paraphrasing generally reduces the models’ vulnerabilities to our proposed attack. We found that the main reason for this ASR decrease is that the prompt after paraphrasing is not as obscure as the original, making it easier to understand and thus reducing the effectiveness of obscure input. However, despite the reduction, the residual ASR, notably the 17.74% for GPT-4’s and 52.54% for ChatGPT , indicates a remaining risk. The variance in the impact of paraphrasing on different models suggests that the models’ underlying architectures and training data might influence their resilience to such attacks. These results underscore the importance of developing more robust models that maintain high resistance to adversarial inputs across both original and paraphrased prompts.
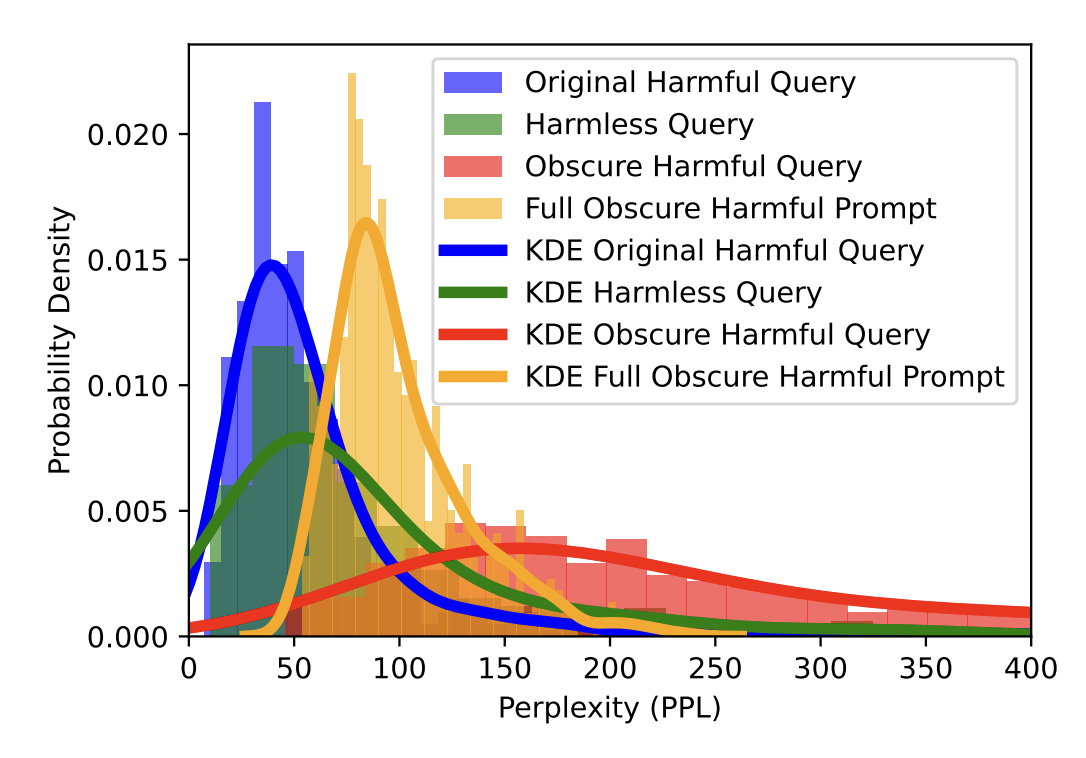
As depicted in Figure, it is evident that the average PPL associated with obscure harmful queries or prompts significantly exceeds that of harmless or original harmful queries. Moreover, an overlap is observed between the distributions of harmless queries and fully obscured harmful prompts. This overlap suggests that relying solely on a PPL-based filter may not provide an effective defense against such attacks, as it could potentially compromise the processing of benign user queries (i.e., harmless queries). This also indicates that ObscurePrompt is robust to PPL-filtering defender.
@misc{huang2024ObscurePromptjailbreakinglargelanguage,
title={ObscurePrompt: Jailbreaking Large Language Models via Obscure Input},
author={Yue Huang and Jingyu Tang and Dongping Chen and Bingda Tang and Yao Wan and Lichao Sun and Xiangliang Zhang},
year={2024},
eprint={2406.13662},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2406.13662},
}